这里有最新的公司动态,这里有最新的网站设计、移动端设计、网页相关内容与你分享!
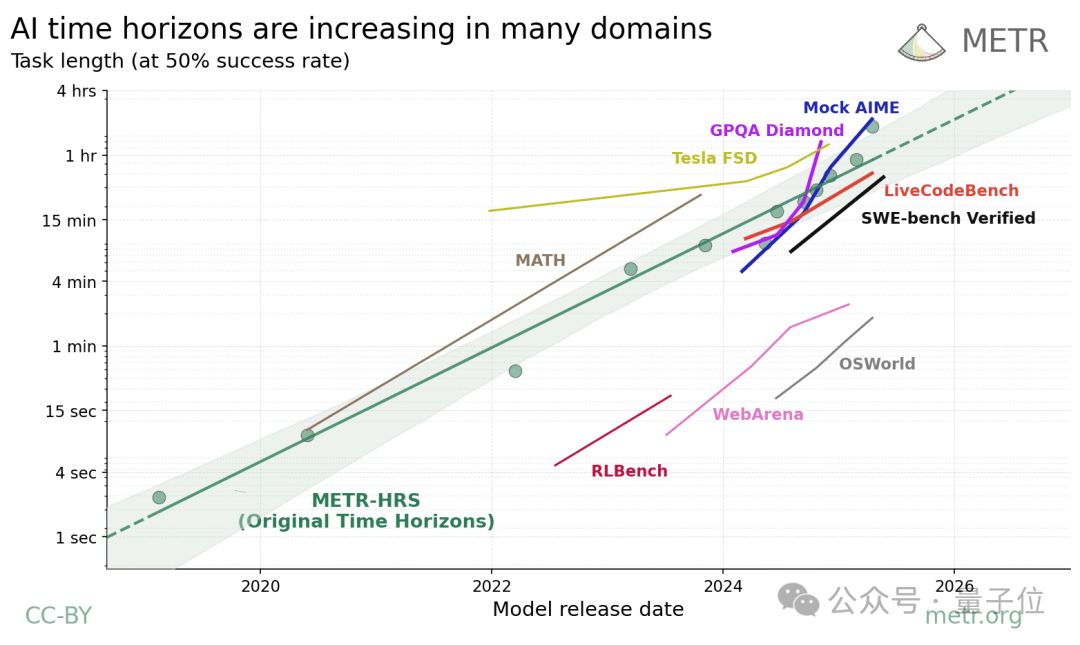 来自Aofeisi Quadrup的Henry |官方帐户QBITAAGENT能力每7个月加倍!根据非营利性研究公司METR发布的一份新报告,该规则已在9个基准测试中得到了证明。这些活动涉及编程,数学,计算机使用,自动驾驶和其他字段,表明大型模型正在不断朝着高自动化发展。该报告指出,在软件开发,数学竞赛,科学问答等任务中,代理商可以完成人们可以花费50-200分钟完成的任务,而这种能力正在迅速提高 - 它可以每2-6个月翻一番。在计算机操作任务中,尽管任务持续时间很短,但增长率与软件开发等活动一致。代理商在自主驾驶活动中的表现的增长率较慢,持续了近20个月。在理解视频的任务中,该模型可以在1小时的视频中获得50%的成功率。作为一个致力于研究切割人工智能系统的能力和风险的研究团队,元R的报告正在缩小AI自治时间表。快来看看报告内容是什么。摩尔在先前试验中的代理定律将重点关注软件和研究的发展活动,并发现AI代理的能力显示出“摩尔法案”的“摩尔法案”的平均增长率 - 每七个月,每隔七个月,即可到达其活动的时间可能会增加一倍。在最新报告中,梅尔(Metr)在更广泛的领域扩展了这种审查方法,并继续提出一个珍珠问题:AI的功能能否继续进行更广泛的任务?但是我们应该问的第一件事是,有什么时候看?扩展全文
例如,如果人们平均花费30分钟完成任务,那么如果AI在此类任务中有成功的一半机会,那么时间为30分钟。如果其成功率高于一半,这意味着它确实可以处理更长,更复杂的任务。
总而言之,到达时间是代理可以在任务中完成稳定的时间。
由于时间越长的时间越长 - 毫升任务≈≈战略性推理和计划功能≈≈量越高,代理人的智能水平越高,触及时间的增量也称为摩尔定律。
因为AI的功能在不同的活动中差异很大,所以现在的问题是:该法律是否在另一个领域建立?
如何测量整个领域的时间-TO -REACH时间?
为了证明上述问题,该报告选择了9个基准,包括软件开发(METR -HRS,SWE -BENCH),计算机使用(OSWORLD,Webarena)和数学竞赛(Mockaime)。
对于每个基准测试,METR都会生成一个可能性的模型,以估计代理时间的到达。该报告使用估计(MLE)的最大可能性或简化的估计程序来处理标签的谷物随着时间的推移,不同基准测试以估计每个域中的AI时间生长曲线。
值得注意的是,不同基准的到达时间的边界与100倍不同。理解和编码的许多基准都聚集了1小时或更长时间,但是计算机使用时间(OSWorld,Webarena)仅约2分钟,这可能是由于使用鼠标时的代理商错误所致。
研究发现,在月球中重复的特工
除了我们首先提到的代理人的功能外,该报告还测试了某些当前基本模型的功能。例如,诸如O3之类的切割模型在METR活动中的赛车水平高于赛车水平,使时间比7个月更快,并且中位数增加9个基准的时间约为4个月(范围为2.5至17个月)。
最后,对于所有主要试验,时间 - 雷奇时间并不重要。因为在某些基准测试中的糟糕问题的困难大于简单问题的问题,而在其他问题上,问题的困难与简单的问题非常相似。因此,对于代理商,时间 - 时间时间并不能完全反映其在这些基准上的性能。
例如,leetcode(livecodebench)和数学问题(AIME)比简单的问题更加困难,但是长视频中的视频mme问题并不比简短的视频更困难。
可以看出,代理商的表现不仅仅是“更多技能”,而且如果它可以处理更长,更复杂的任务。
从几秒钟,分钟到十二分钟,小时,代理处理的范围在水平上增加;如果趋势的增加一倍,可以看到AI在未来几年完成“天→周”任务。
这项研究的摘要可以看到一项纳帕克勒规则:从推理代码到数学竞赛,从GUI控制到自主驾驶,没有工作领域显示出智能增长的“疲劳”。在大多数情况下,AI朝着较大的跨度出现,更深的记忆和更复杂的计划全速计划。
参考链接:
[1] https://arxiv.org/abs/2503.14499
整个域/回到Sohu以查看更多
来自Aofeisi Quadrup的Henry |官方帐户QBITAAGENT能力每7个月加倍!根据非营利性研究公司METR发布的一份新报告,该规则已在9个基准测试中得到了证明。这些活动涉及编程,数学,计算机使用,自动驾驶和其他字段,表明大型模型正在不断朝着高自动化发展。该报告指出,在软件开发,数学竞赛,科学问答等任务中,代理商可以完成人们可以花费50-200分钟完成的任务,而这种能力正在迅速提高 - 它可以每2-6个月翻一番。在计算机操作任务中,尽管任务持续时间很短,但增长率与软件开发等活动一致。代理商在自主驾驶活动中的表现的增长率较慢,持续了近20个月。在理解视频的任务中,该模型可以在1小时的视频中获得50%的成功率。作为一个致力于研究切割人工智能系统的能力和风险的研究团队,元R的报告正在缩小AI自治时间表。快来看看报告内容是什么。摩尔在先前试验中的代理定律将重点关注软件和研究的发展活动,并发现AI代理的能力显示出“摩尔法案”的“摩尔法案”的平均增长率 - 每七个月,每隔七个月,即可到达其活动的时间可能会增加一倍。在最新报告中,梅尔(Metr)在更广泛的领域扩展了这种审查方法,并继续提出一个珍珠问题:AI的功能能否继续进行更广泛的任务?但是我们应该问的第一件事是,有什么时候看?扩展全文
例如,如果人们平均花费30分钟完成任务,那么如果AI在此类任务中有成功的一半机会,那么时间为30分钟。如果其成功率高于一半,这意味着它确实可以处理更长,更复杂的任务。
总而言之,到达时间是代理可以在任务中完成稳定的时间。
由于时间越长的时间越长 - 毫升任务≈≈战略性推理和计划功能≈≈量越高,代理人的智能水平越高,触及时间的增量也称为摩尔定律。
因为AI的功能在不同的活动中差异很大,所以现在的问题是:该法律是否在另一个领域建立?
如何测量整个领域的时间-TO -REACH时间?
为了证明上述问题,该报告选择了9个基准,包括软件开发(METR -HRS,SWE -BENCH),计算机使用(OSWORLD,Webarena)和数学竞赛(Mockaime)。
对于每个基准测试,METR都会生成一个可能性的模型,以估计代理时间的到达。该报告使用估计(MLE)的最大可能性或简化的估计程序来处理标签的谷物随着时间的推移,不同基准测试以估计每个域中的AI时间生长曲线。
值得注意的是,不同基准的到达时间的边界与100倍不同。理解和编码的许多基准都聚集了1小时或更长时间,但是计算机使用时间(OSWorld,Webarena)仅约2分钟,这可能是由于使用鼠标时的代理商错误所致。
研究发现,在月球中重复的特工
除了我们首先提到的代理人的功能外,该报告还测试了某些当前基本模型的功能。例如,诸如O3之类的切割模型在METR活动中的赛车水平高于赛车水平,使时间比7个月更快,并且中位数增加9个基准的时间约为4个月(范围为2.5至17个月)。
最后,对于所有主要试验,时间 - 雷奇时间并不重要。因为在某些基准测试中的糟糕问题的困难大于简单问题的问题,而在其他问题上,问题的困难与简单的问题非常相似。因此,对于代理商,时间 - 时间时间并不能完全反映其在这些基准上的性能。
例如,leetcode(livecodebench)和数学问题(AIME)比简单的问题更加困难,但是长视频中的视频mme问题并不比简短的视频更困难。
可以看出,代理商的表现不仅仅是“更多技能”,而且如果它可以处理更长,更复杂的任务。
从几秒钟,分钟到十二分钟,小时,代理处理的范围在水平上增加;如果趋势的增加一倍,可以看到AI在未来几年完成“天→周”任务。
这项研究的摘要可以看到一项纳帕克勒规则:从推理代码到数学竞赛,从GUI控制到自主驾驶,没有工作领域显示出智能增长的“疲劳”。在大多数情况下,AI朝着较大的跨度出现,更深的记忆和更复杂的计划全速计划。
参考链接:
[1] https://arxiv.org/abs/2503.14499
整个域/回到Sohu以查看更多 Copyright © 2024-2026 吃瓜黑料爆料网站-爆料黑料网站-爆料快手网红黑料网站 版权所有
沪ICP备32623652号-1